PDAL Architecture Overview
- Author:
Andrew Bell
- Contact:
- Date:
5/15/2016
PDAL is a set of applications and library to facilitate translation of point cloud data between various formats. In addition, it provides some facilities for transformation of data between various geometric projections and can calculate some statistical, boundary and density data. PDAL also provides point classification algorithms. PDAL provides an API that can be used by programmers for integration into their own projects or to allow extension of existing capabilities.
The PDAL model
PDAL reads data from a set of input sources using format-specific readers. Point data can be passed through various filters that transform data or create metadata. If desired, points can be written to an output stream using a format-specific writer. PDAL can merge data from various input sources into a single output source, preserving attribute data where supported by the input and output formats.
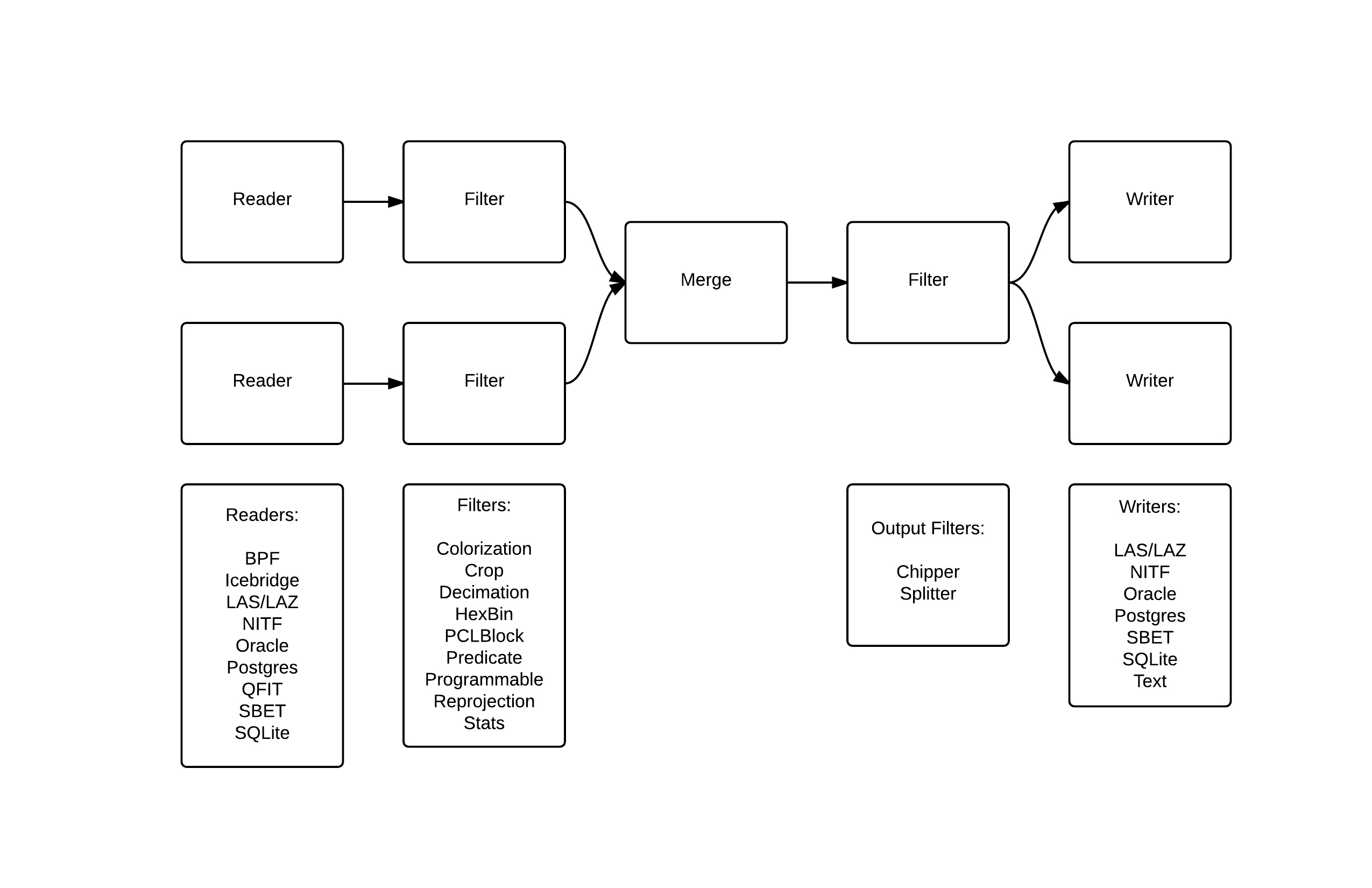
The above diagram shows a possible arrangement of PDAL readers, filters and writers, all of which are known as stages. Any merge operation or filter may be placed after any reader. Output filters are distinct from other filters only in that they may create more than one set of points to be further filtered or written. The arrangement of readers, filters and writers is called a PDAL pipeline. Pipelines can be specified using JSON as detailed later.
Extending PDAL
PDAL is simple to extend by implementing subclasses of existing stages. All processing in PDAL is completely synchronous. No parallel processing occurs, eliminating locking or other concurrency issues. Understanding of several auxiliary classes is necessary to effectively create a new stage.
Dimension
Point cloud formats support various data elements. In order to be useful, all formats must provide some notion of location for points (X, Y and perhaps Z), but beyond that, the data collected in formats may or may not have common data fields. Some formats predefine the elements that make up a point. Other formats provide this information in a header or preamble. PDAL calls each of the elements that make up a point a dimension. PDAL predefines the dimensions that are in common use by the formats that it currently supports. Readers may register their use of a predefined dimension or may have PDAL create a dimension with a name and type as requested. Dimensions are described in a JSON file, Dimension.json.
PDAL has a default type (Double, Float, Signed32, etc.) for each of its predefined dimensions which is believed to be sufficient to accurately hold the necessary data. Only when the default data type is deemed insufficient should a request be made to “upgrade” a storage datatype. There is no simple facility to “downsize” a dimension type to save memory, though it can be done by creating a custom PointLayout object. Dimension.json can be examined to determine the default storage type of each predefined dimension. In most cases knowledge of the storage data type for a dimension isn’t required. PDAL properly converts data to and from the internal storage type transparently. Invalid conversions raise an exception.
When a storage type is explicitly requested for a dimension, PDAL examines the existing storage type and requested type and chooses the storage type so that it can hold both types. In some cases this results in a storage type different from either the existing or requested storage type. For instance, if the current storage type is a 16 bit signed integer (Signed16) and the requested type is a 16 bit unsigned integer (Unsigned16), PDAL will use a 32 bit signed integer as the storage type for the dimension so that both 16 bit storage types can be successfully accommodated.
Point Layout
PDAL stores the dimension information in a point layout structure (PointLayout object). It stores information about the physical layout of data of each point in memory and also stores the type and name of each dimension.
Point Table
PDAL stores points in what is called a point table (PointTable object). Each point table has an associated point layout describing its format. All points in a single point table have the same dimensions and all operations on a PDAL pipeline make use of a single point table. In addition to storing points, a point table also stores pipeline metadata that may be created as pipeline stages are executed. Most functions receive a PointTableRef object, which refers to the active point table. A PointTableRef can be stored or copied cheaply.
A subclass of PointTable called StreamingPointTable exists to allow a pipeline to run without loading all points in memory. A StreamingPointTable holds a fixed number of points. Some filters can’t operate in streaming mode and an attempt to run a pipeline with a stage that doesn’t support streaming will raise an exception.
Point View
A point view (PointView object) stores references to points. Storage and retrieval of points is done through a point view rather than directly through a point table. Point data is accessed from a point view through a point ID (type PointId), which is an integer value. The first point reference in a point view has a point ID of 0, the second has a point ID of 1, the third has a point ID of 2 and so on. There are no null point references in a point view. The size of a point view is the number of point references contained in the view. A point view acts like a self-expanding array or vector of point references, but it is always full. For example, one can’t set the field value of point with a PointId of 9 unless there already exist at least 8 point references in the point view.
Point references can be copied from one point view to another by appending an existing reference to a destination point view. The point ID of the appended point in the destination view may be different than the point ID of the same point in the source view. The point ID of an appended point reference is the same as the size of the point view after the operation. Note that appending a point reference does not create a new point. Rather, it creates another reference to an existing point. There are currently no built-in facilities for creating copies of points.
Point Reference
Some functions take a reference to a single point (PointRef object). In streaming mode, stages implement the processOne() function which operates on a point reference instead of a point view.
Making a Stage (Reader, Filter or Writer):
All stages (Stage object) share a common interface, though readers, filters and writers each have a simplified interface if the generic stage interface is more complex than necessary. One should create a new stage by creating a subclass of reader (Reader object), filter (Filter object) or writer (Writer object). When a pipeline is made, each stage is created using its default constructor.
When a pipeline is started, each of its stages is processed in two distinct steps. First, all stages are prepared.
Stage Preparation
Preparation of a stage is done by calling the prepare() function of the stage at the end of the pipeline. prepare() executes the following private virtual functions calls, none of which need to be implemented in a stage unless desired. Each stage is guaranteed to be prepared after all stages that precede it in the pipeline.
void addArgs(ProgramArgs& args)
Stages can accept various options to control processing. These options can be declared and bound to variables in this function. When arguments are added, the stage also provides a description and optionally a default value for the argument.
void initialize() OR void initialize(PointTableRef)
Some stages, particularly readers, may need to do things such as open files to extract header information before the next step in processing. Other general processing that needs to take place before any stage is executed should occur at this time. If the initialization requires knowledge of the point table, implement the function that accepts one, otherwise implement the no-argument version. Whether to place initialization code at this step or in prepared() or ready() (see below) is a judgment call, but detection of errors earlier in the process allows faster termination of a command. Files opened in this step should also be closed before returning.
void addDimensions(PointLayoutPtr layout)
This method allows stages to inform a point table’s layout of the dimensions that it would like as part of the record of each point. Usually, only readers add dimensions to a point table, but there is no prohibition on filters or writers from adding dimensions if necessary. Dimensions should not be added to the layout outside of this method.
void prepared(PointTableRef)
Called after dimensions are added. It can be used to verify state and raise exceptions before stage execution.
Stage Execution
After all stages are prepared, processing continues with the execution of each stage by calling execute(). Each stage will be executed only after all stages preceding it in a pipeline have been executed. A stage is executed by invoking the following private virtual methods. It is important to note that ready() and done() are called only once for each stage while run() is called once for each point view to be processed by the stage.
void ready(PointTablePtr table)
This function allows preprocessing to be performed prior to actual processing of the points in a point view. For example, filters may initialize internal data structures or libraries, readers may connect to databases and writers may write a file header. If there is a choice between performing operations in the preparation stage (in the initialize() method) or the execution stage (in ready()), prefer to defer the operation until this point.
PointViewSet run(PointViewPtr buf)
This is the method in which processing of individual points occurs. One might read points into the view, transform point values in some way, or distribute the point references in the input view into numerous output views. This method is called once for each point view passed to the stage.
void done(PointTablePtr table)
This function allows a stage to clean up resources not released by a stage’s destructor. It also allows other execution of termination functions, such a closing of databases, writing file footers, rewriting headers or closing or renaming files.
Streaming Stage Execution
PDAL normally processes all points through each stage before passing the points to the next stage. This means that all point data is held in memory during processing. There are some situations that may make this undesirable. As an alternative, PDAL allows execution of data with a point table that contains a fixed number of points (StreamPointTable). When a StreamPointTable is passed to the execute() function, the private run() function detailed above isn’t called, and instead processOne() is called for each point. If a StreamPointTable is passed to execute() but a pipeline stage doesn’t implement processOne(), an exception is thrown.
bool processOne(PointRef& ref)
This method allows processing of a single point. A reader will typically read a point from an input source. When a reader returns ‘false’ from this function, it indicates that there are no more points to be read. When a filter returns ‘false’ from this function, it indicates that the point just processed should be filtered out and not passed to subsequent stages for processing.
Implementing a Reader
A reader is a stage that takes input from a point cloud format supported by PDAL and loads points into a point table through a point view.
A reader needs to register or assign those dimensions that it will reference when adding point data to the point table. Dimensions that are predefined in PDAL can be registered by using the point table’s registerDim() method. Dimensions that are not predefined can be added using assignDim(). If dimensions are determined as named entities from a point cloud source, it may not be known whether the dimensions are predefined or not. In this case the function registerOrAssignDim() can be used. When a dimension is assigned, rather than registered, the reader needs to inform PDAL of the type of the variable using the enumeration Dimension::Type.
In this example, the reader informs the point table’s layout that it will reference the dimensions X, Y and Z.
void Reader::addDimensions(PointLayoutPtr layout) { layout->registerDim(Dimension::Id::X); layout->registerDim(Dimension::Id::Y); layout->registerDim(Dimension::Id::Z); }
Here a reader determines dimensions from an input source and registers or assigns them. All of the input dimension values are in this case double precision floating point.
void Reader::addDimensions(PointLayoutPtr layout)
{
FileHeader header;
for (auto di = header.names.begin(), di != header.names.end(); ++di)
{
std::string dimName = *di;
Dimension::Id id = layout->registerOrAssignDim(dimName,
Dimension::Type::Double);
}
}
If a reader implements initialize() and opens a source file during the function, the file should be closed again before exiting the function to ensure that file handles aren’t exhausted when processing a large number of files.
Readers should use the ready() function to reset the input data to a state where the first point can be read from the source. The done() function should be used to free resources or reset the state initialized in ready().
Readers should implement a function, read(), that will place the data from the input source into the provided point view:
point_count_t read(PointViewPtr view, point_count_t count)
The reader should read at most ‘count’ points from the input source and place them in the view. The reader must keep track of its current position in the input source and points should be read until no points remain or ‘count’ points have been added to the view. The current location in the input source is typically tracked with a integer variable called the index.
As each point is read from the input source, it must be placed at the end of the point view. The ID of the end of the point view can be determined by calling size() function of the point view. read() should return the number of points read by during the function call.
point_count_t MyFormat::read(PointViewPtr view, point_count_t count) { // Determine the number of points remaining in the input. point_count_t remainingInput = m_totalNumPts - m_index; // Determine the number of points to read. count = std::min(count, remainingInput); // Determine the ID of the next point in the point view PointId nextId = view->size(); // Determine the current input position. auto pos = m_pointSize * m_index; point_count_t remaining = count; while (remaining--) { double x, y, z; // Read X, Y and Z from input source. x = m_file.read<double>(pos); pos += sizeof(double); y = m_file.read<double>(pos); pos += sizeof(double); z = m_file.read<double>(pos); pos += sizeof(double); // Set X, Y and Z into the pointView. view->setField(Dimension::Id::X, nextId, x); view->setField(Dimension::Id::Y, nextId, y); view->setField(Dimension::Id::Z, nextId, z); nextId++; } m_index += count; return count; }Note that we don’t read more points than requested, we don’t read past the end of the input stream and we keep track of our location in the input so that subsequent calls to read() will result in all points being read.
Here’s the same function written so that streaming can be supported:
point_count_t MyFormat::read(PointViewPtr view, point_count_t count) { // Determine the number of points remaining in the input. point_count_t remainingInput = m_totalNumPts - m_index; // Determine the number of points to read. count = std::min(count, remainingInput); // Determine the ID of the next point in the point view PointId nextId = view->size(); // Determine the current input position. auto pos = m_pointSize * m_index; point_count_t remaining = count; while (remaining--) { PointRef point(view->point(nextId)); processOne(point); nextId++; } m_index += count; return count; } bool MyFormat::processOne(PointRef& point) { double x, y, z; // Read X, Y and Z from input source. x = m_file.read<double>(pos); pos += sizeof(double); y = m_file.read<double>(pos); pos += sizeof(double); z = m_file.read<double>(pos); pos += sizeof(double); point.setField(Dimension::Id::X, x); point.setField(Dimension::Id::Y, y); point.setField(Dimension::Id::Z, z); return m_file.ok(); }
Implementing a Filter
A filter is a stage that allows processing of data after it has been read into a pipeline’s point table. In many filters, the only function that need be implemented is filter(), a simplified version of the stage’s run() method whose input and output is a point view provided by the previous stage:
void filter(PointViewPtr view)
One should implement filter() instead of run() if its interface is sufficient. The expectation is that a filter will iterate through the points currently in the point view and apply some transformation or gather some data to be output as pipeline metadata.
Here as an example is the actual filter function from the reprojection filter:
void Reprojection::filter(PointViewPtr view) { for (PointId id = 0; id < view->size(); ++id) { double x = view->getFieldAs<double>(Dimension::Id::X, id); double y = view->getFieldAs<double>(Dimension::Id::Y, id); double z = view->getFieldAs<double>(Dimension::Id::Z, id); transform(x, y, z); view->setField(Dimension::Id::X, id, x); view->setField(Dimension::Id::Y, id, y); view->setField(Dimension::Id::Z, id, z); } }The filter simply loops through the points, retrieving the X, Y and Z values of each point, transforms those value using a reprojection algorithm and then stores the transformed values in the point table using the point view’s setField() function.
A filter may need to use the run() function instead of filter(), typically because it needs to create multiple output point views from a single input view. The following example puts every other input point into one of two output point views:
PointViewSet Alternator::run(PointViewPtr view) { PointViewSet viewSet; PointViewPtr even = view(); PointViewPtr odd = view(); viewSet.insert(even); viewSet.insert(odd); for (PointId idx = 0; idx < view->size(); ++idx) { PointViewPtr out = idx % 2 ? even : odd; out->appendPoint(*view.get(), idx); } return viewSet; }
Implementing a Writer:
Analogous to the filter() method in a filter is the write() method of a writer. This function is usually the appropriate one to override when implementing a writer – it would be unusual to need to implement run(). A typical writer will open its output file when ready() is called, write individual points in write() and close the file in done().
Like a filter, a writer may receive multiple point views during processing of a pipeline. This will result in the write() function being called once for each of the input point views. Writers may produce a separate output file for each input point view or may produce a single output file. The documentation should clearly state this behavior. Placing a merge filter in front of a writer in the pipeline will make sure that a single point view is passed to the writer.
As new writers are created, developers should try to make sure that they behave reasonably if passed multiple point views – they correctly handle write() being called multiple times after a single call to ready().
void write(const PointViewPtr view)
{
ostream& out = *m_out;
for (PointId id = 0; id < view->size(); ++id)
{
out << setw(10) << view->getFieldAs<double>(Dimension::Id::X, id);
out << setw(10) << view->getFieldAs<double>(Dimension::Id::Y, id);
out << setw(10) << view->getFieldAs<double>(Dimension::Id::Z, id);
}
}
bool processOne(PointRef& point)
{
out << setw(10) << point.getFieldAs<double>(Dimension::Id::X);
out << setw(10) << point.getFieldAs<double>(Dimension::Id::Y);
out << setw(10) << point.getFieldAs<double>(Dimension::Id::Z);
}